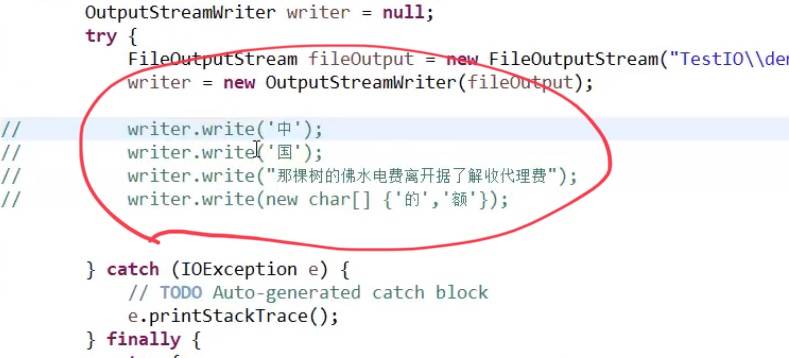
在OutputStreamWriter中,也是有缓冲区:同理,在catch前面定义一个刷新缓冲区,以免在关闭的时候出现异常无法显示数据:
write.flush();

在OutputStreamWriter中,也是有缓冲区:同理,在catch前面定义一个刷新缓冲区,以免在关闭的时候出现异常无法显示数据:
write.flush();
因为内部的流被包装流所管理,所以关闭流的时候关闭包装流即可。
06:35
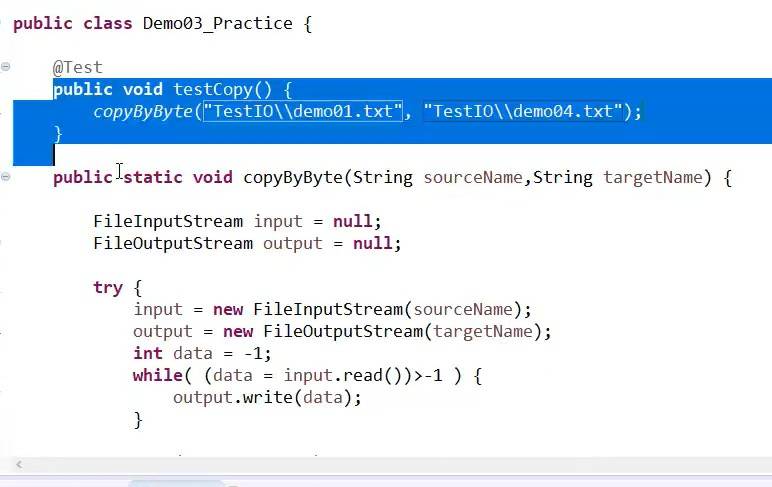
为了让代码的方法通用性更强,我们把源文件和目标文件两个文件作为参数传递给copyByByte方法,再单独创建一个test测试方法。
个人总结:
1、当我们需要读取字节数据,也就是执行输入操作的时候,需要定义一个a=-1,然后接着一个while循环去判断:
int a=-1;
while(true){
a=input.read();
if(a==-1)break;
System.put.print((char)a);
}
2、当我们需要通过数组实现文件读取的时候,也就是执行输入操作的时候,需要定义data字节数组,并且定义int length=-1;接着通过遍历的方法执行循环:
方法一:
byte[] data=new byte[4];
int length=-1;
while(length=input.read(data))>-1){
for(int i=0;i<length;i++){
System.out.print((char)data[i]);
}
方法二:
byte[] data=new byte[1024];
int length=-1;
while(length=input.read(data)!=-1)
{length=input.read(data));
String str= new String(data,0,length);
System.out.print(str);}
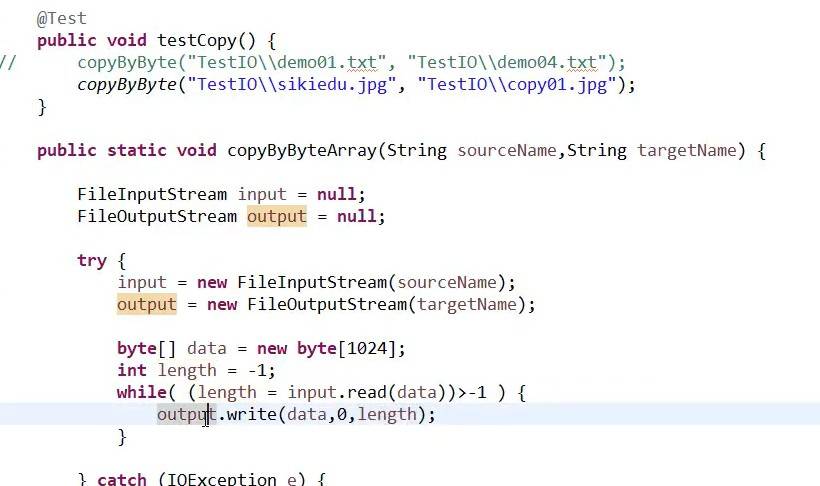
3、当我们需要通过数组实现完成文件的复制的时候,
byte[] data=new byte[1024];
int length=-1;
while(length=input.read(data)!=-1)
{output.write(data,0,length);}
缓冲区输入流中缓冲区没有刷新这一说,因为我们只需要读取,而不是写入。
缓冲区输入流中缓冲区承担的作用:读取字节的时候,每读一个字节,都要跟硬盘交互一次,浪费性能。
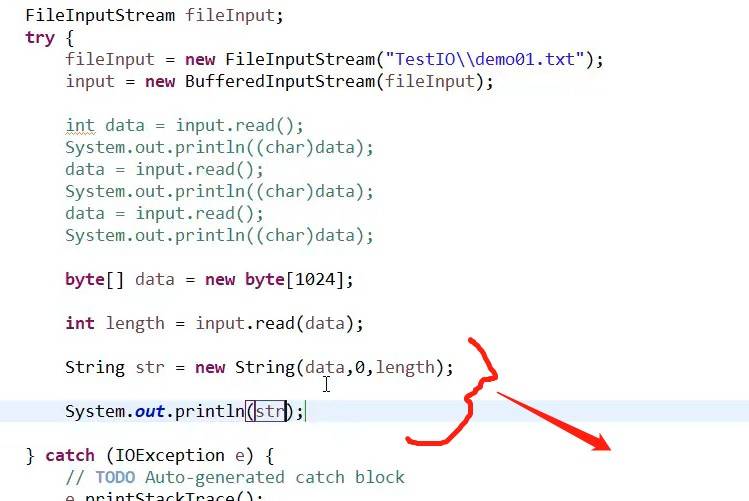
因为字节数组比较大,为1024,我们去读一次就读取完了,所以不采用遍历方法;但是也可以使用遍历的方法把文本的内容读取(如任务41:当中的字节数组为4,jiao'xiao):
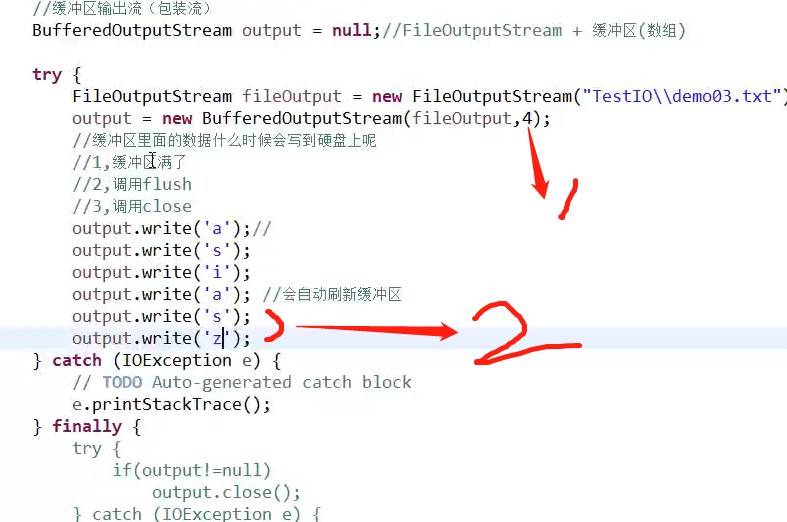
1:4表示缓冲区的大小
2:因为缓冲区大小为4,所以当存到第二个a的时候,会自动刷新缓冲区,缓冲区把自身数据写入到硬盘上。所以,s和z没有写到硬盘上,因为缓冲区没满。
以防close出现异常,导致缓冲区的数据写不到硬盘上,在执行close前先执行output.flush();
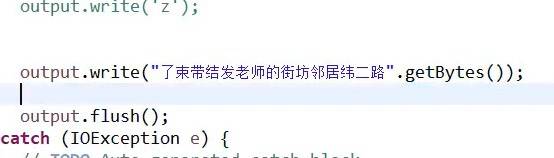
把字符串转换成字节类型(getBytes())并通过字节数组写入到缓冲区。
缓冲区:把写入的内容暂时存放在缓冲区内,待填满缓冲区或写入内容完毕时,,系统会一次性把缓冲区内容跟硬盘之间进行数据交互。
output.flush();//刷新缓冲区,把缓冲区内容写到硬盘上,达成数据输出。
缓冲区里面的数据什么时候会写到硬盘上呢?
1、缓冲区满了
2、调用flush//流并没有关闭,仍可以实现单个字节的shu'chu
3、调用close
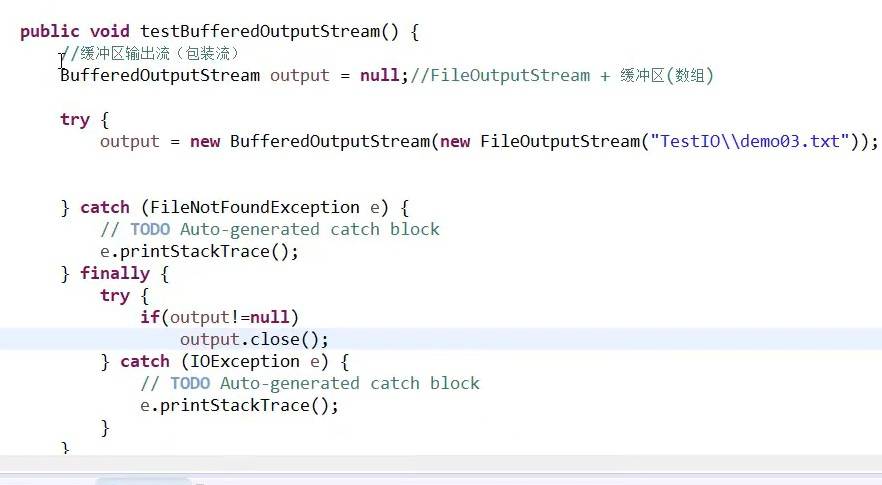 不可以直接给BufferedOutPutStream传递一个路径对象,需要new一个FileOutputStream对象,再把路径对象放在FileOutputStream里面。
不可以直接给BufferedOutPutStream传递一个路径对象,需要new一个FileOutputStream对象,再把路径对象放在FileOutputStream里面。
--所以,缓冲区输出流也叫包装流:对其他流进行包装。(给原有的流加了个包装流,俗称缓冲区输出流)

关闭的时候关闭包装流就可以了:
使用字节数组完成文件的复制:
统计字节完成文件的复制时间以及字节数组完成文件的复制时间:
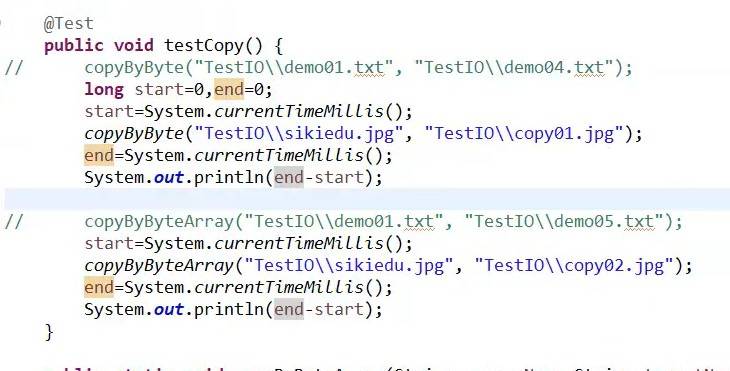
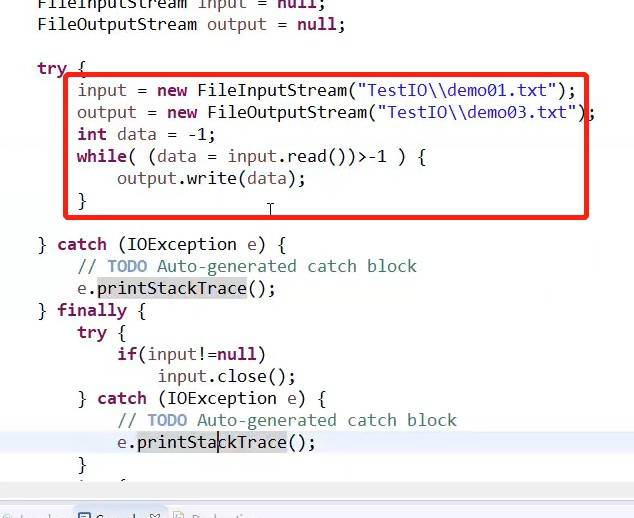 一边读入一边写出,从而进行使用文件输入输出流复制文件。
一边读入一边写出,从而进行使用文件输入输出流复制文件。
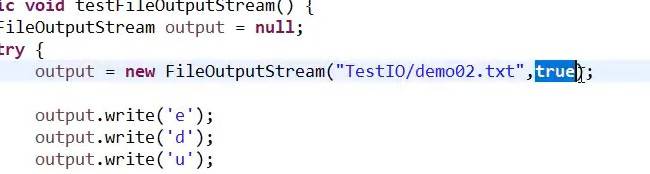
假如添加一个true属性,会把write写入内容变成追加;假如不添加true,系统会默认为false,则会把原来内容替换掉。
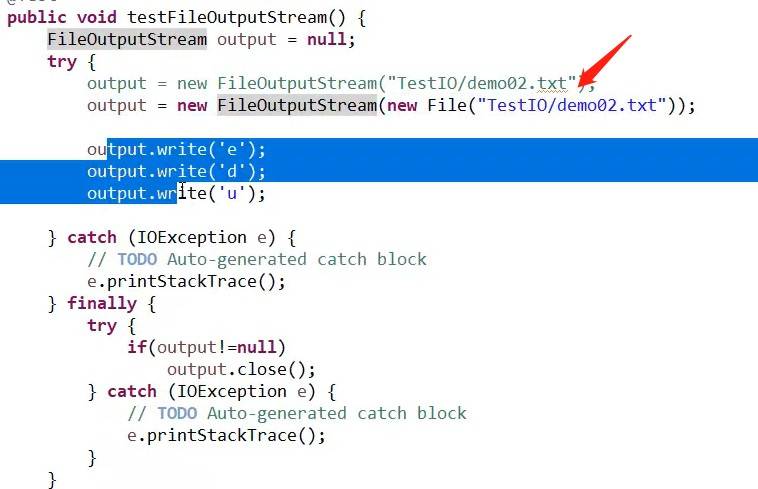
getBytes()可以把字符串转换成字节:

------
输入流:把中文读取出来需要我们去处理字节问题,而我们不知道字节是多少,所以通过输入流无法显示中文;
输出流:把中文输出到指定位置,也就是把中文这个字节写进去,系统会帮我们处理中文的字节问题。
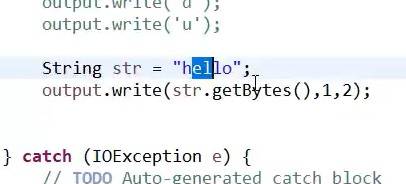
读取索引为1至2之间的所有字符:el
因为要对流的关闭操作,所以无论是输入流还是输出流,我们都要把这个流定义在try catch外面:
FileOutPutStream output=null;
对流的关闭操作也需要try catch。
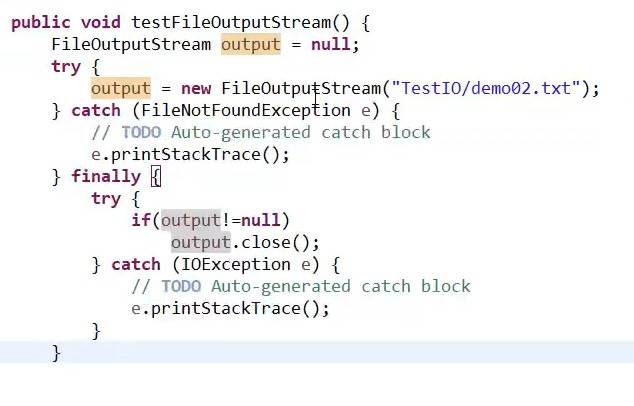
当我们进行输出流操作时,输出对象不存在,系统会自动变我们生成。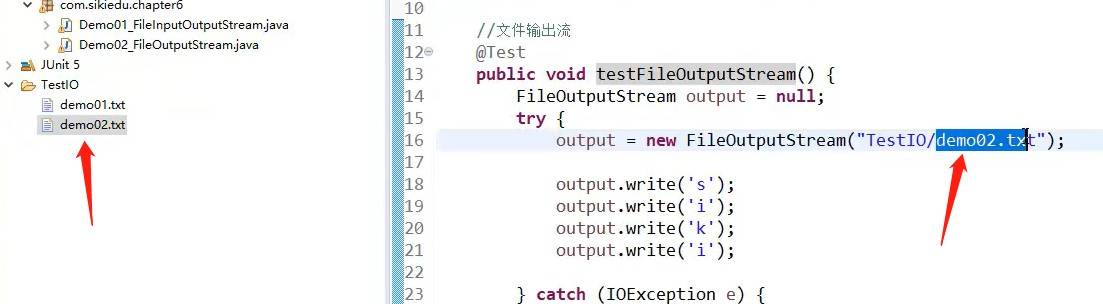
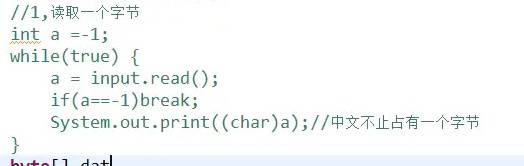
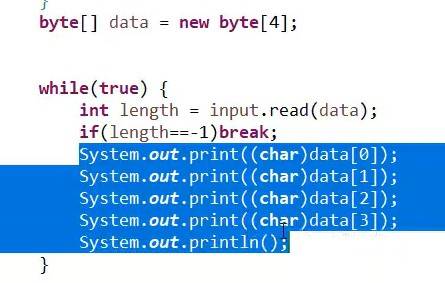
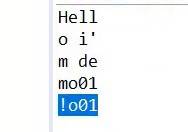
因为每四个字节四个字节去读取,当读完data【3】的时候,最后剩下一个!还没读取,这个时候感叹号就会取代data【3】里面的m,o01接着感叹号一同输出。
所以,我们借助遍历方法进行优化:如1
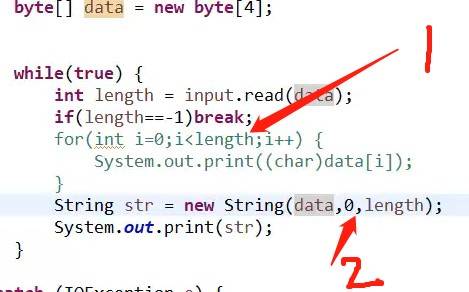
2:把data这个字节数组传递过来,让str一个一个读取字节数组里面的字节并且拼接成字符串输出;0代表开始区间,读取length个字节。
--length:代表读取到的字节数量
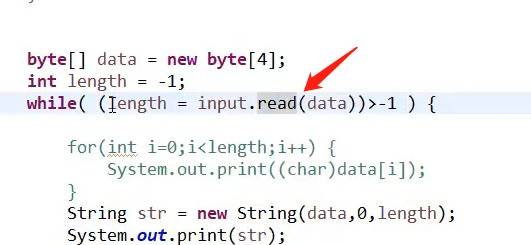
箭头处:1、先进行读取数据,把读取数据存放在data中作为输入流被read,接着把读取到的个数赋值给length,最后跟-1作比较,大于-1才会执行下面循环。
同理:

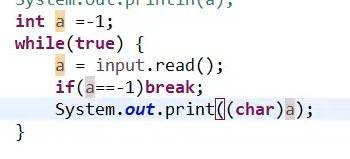
当读取到文本内容最后一个字符的时候,也就是文本末尾(a=-1),循环会break.
因为demo1.txt的字节文件每个字符都是使用字节来存储,所以我们可以每读到一个字节,我们就将他转换成字符类型输出出来。
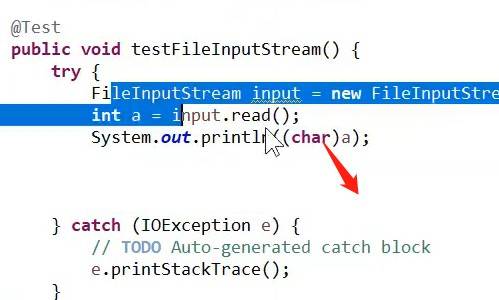
这里如果不把a强制转换成char类型,结果会输出输入流文件的第一个字符对应的ASCII值。
输入流的关闭一般放在finally{}里面:
finally{input.close();}
但是要是放在try里面,有可能因为代码出现异常直接跳到catch部分,无法执行到输入流的关闭。
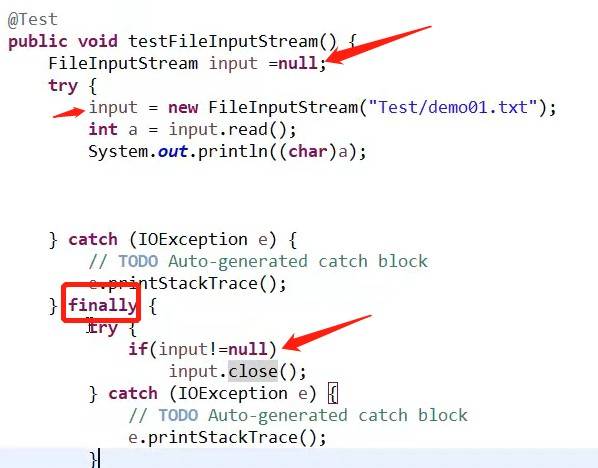
假如在finally里面想要访问input,则需要在try上面定义一个:FileInputStream input=null;
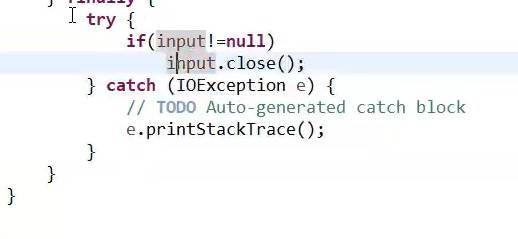
在进行输入流关闭的时候,需要对input进行判断(假如input是null,无需关闭输入流);因为输入流关闭也会出现异常(需要catch异常),所以需要给close定义一个异常处理:
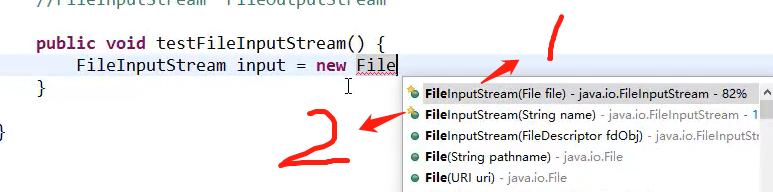
1:因为这个file也是根据文件路径创建的
2:这里的String name就是一个文件路径(绝对路径或者相对路径也可以)
输入流:把文件从硬盘读取到内存里面-》读取-》读入-》输入-》Input-》输入流
输出流:从内存里面把数据保存到硬盘-》存储-》写入-》输出-》Output-》输出流
字符流:只可以读取文本数据
--抽象基类:Reader Writer
字节流:可以读取任意类型的数据
--抽象基类:InputStream OutputStream
字节流用来操作二进制数据,字符流用来操作文本数据。所有数据都是由字节来存储的,所以文本数据也可以用字节流来操作(少数)。

复制用copy:
source:要复制的文件路径;
target:把文件复制到的路径下
剪贴用renameTo
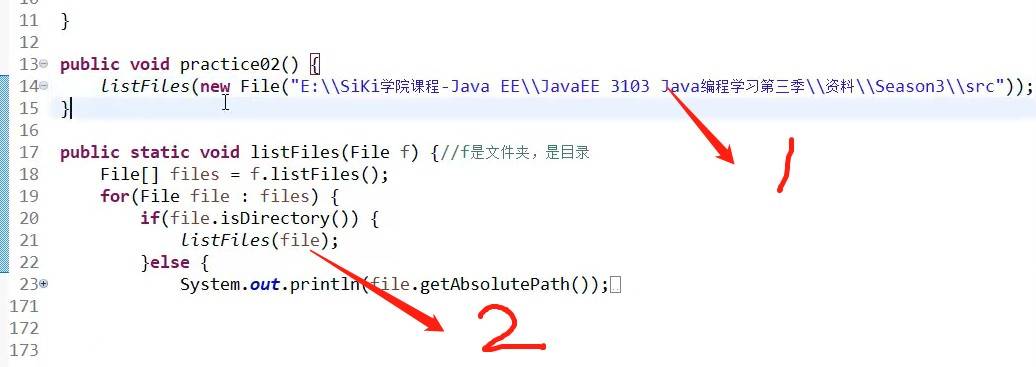
1:把想要遍历的目录传递过来;
2:对目录file进行递归操作